
The power of narratives
Markets are driven as much by sentiments and stories, as by discounted future scenarios. This week we witnessed a dramatic swing in the AI narrative triggered by an unexpected player from China.

In the ever-evolving theater of market psychology, narratives act as powerful forces shaping investor behavior. Like Howard Marks' pendulum metaphor suggests, these narratives swing between extremes, carrying market sentiment along their arc. You could even track this from some of my related posts over time.
This week we witnessed such a dramatic swing in the AI narrative triggered by an unexpected player from China - DeepSeek, an open source LLM provider funded by a quant hedge fund.
No more energy? No more capex? No more compute?
DeepSeek released its latest R1 reasoning model, the latest set of models that can reason and constantly check for logic in their output. It was apparently trained with much less compute and memory requirements (and consequently training costs) at both training and inference stages.
They used a method called distillation - think of it as creating a highly efficient student model that learns from a more powerful teacher model. This approach allows the student model to maintain most of the teacher's capabilities while requiring significantly less computational power and memory.
The concept was around for some time, but the reason it sent a shock through the public and private markets’ system was the disintegration of the currently held beliefs:
That superior AI requires massive computational resources and energy and the access to compute was a constraint. Hence we need more data centres and more power. Big Tech can do it at scale spending billions in capex - the scale moat.
That only the biggest tech companies could afford to compete. The conventional wisdom held that training state-of-the-art AI models required massive capital investments in compute infrastructure. DeepSeek's use of distillation - essentially teaching a smaller model to mimic a larger one's capabilities challenges this assumption head on. - the capital moat.
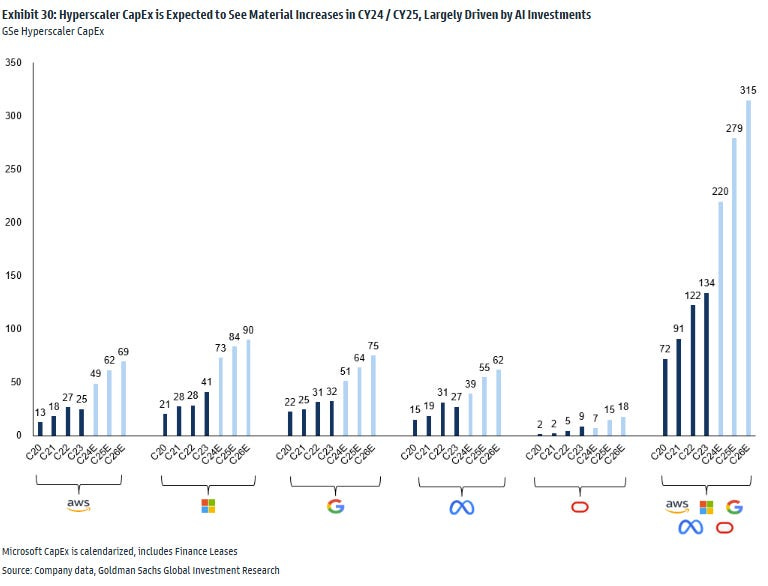
That Nvidia's GPU dominance was unassailable - Nvidia's seeming invincibility in the GPU space for training AI models has been a cornerstone of the AI boom. Their GPUs are optimized for machine learning with superior FLOPS per dollar per watt metrics (used to compare the computational cost of different machine learning models, helping to understand how much processing power is required to run them). They are also most efficient when it comes to the networking between the GPUs themselves and the memory components. For better models you needed more sophisticated and more expensive chips that worked best with Nvidia’s own platform. DeepSeek's achievement using older, less sophisticated chips suggests this moat might be narrower than previously thought. - the GPU moat

The winner take all narrative in AI was also directly challenged as a new disruptor stepped into town.
The most important trend in finance in the past 40 years is the emergence of winner-take-all industry structures in technology. We live in a world of network effects and increasing returns to scale. In industries from PC software (Microsoft), internet search (Alphabet), online retail (Amazon) and social media (Meta) to high-end consumer hardware (Apple), most of the profits and market share have gone to one company. It is only a moderate exaggeration to say all that has mattered for investors in the past few decades was being on the right side of one or more of these winner-take-all stories. - Robert Armstrong, Financial Times
The markets reacted as they always do, wiping out almost a trillion dollars in market cap from the AI infrastructure basket.
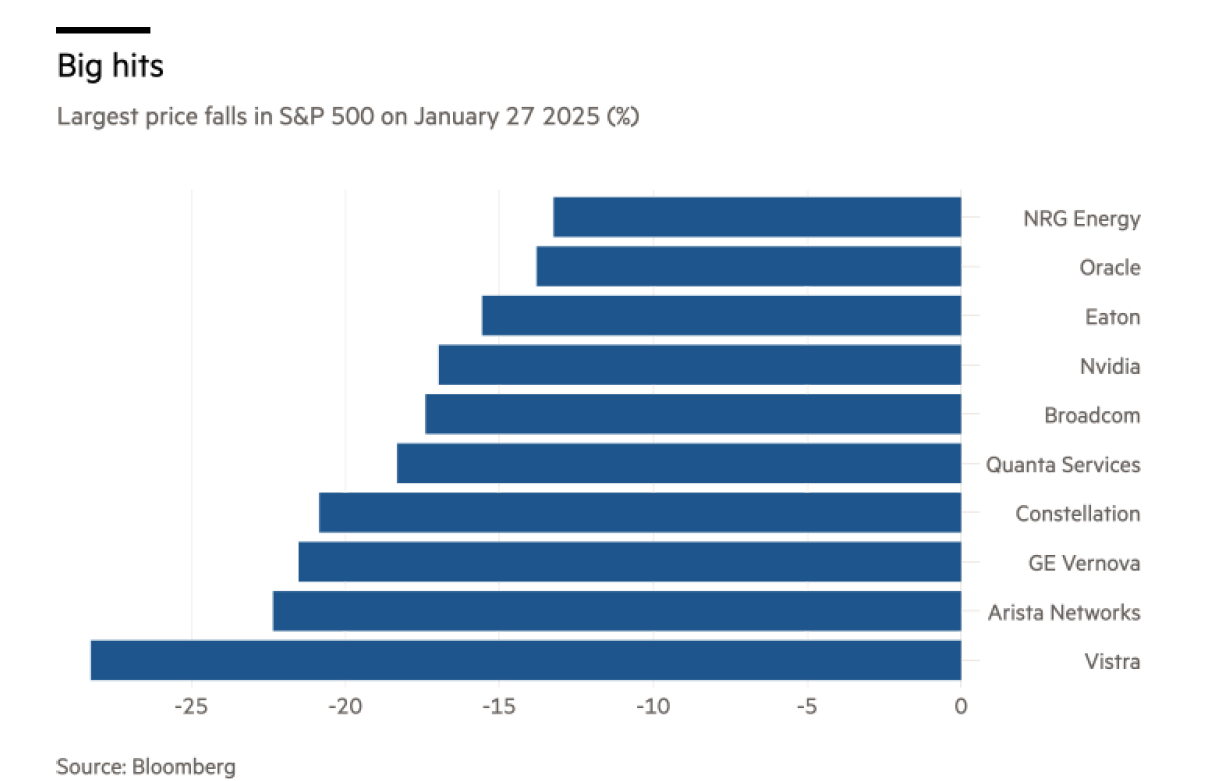
Fresh narratives and fresher debates
We quickly moved on to new narratives as the DeepSeek moment updated our priors and opened a fresh set of debates.
Move over pre-training, Inference is here
An already evolving narrative being widely discussed in podcasts and research papers. That the marginal gains in model output and performance was reaching its limits due to data scarcity and lack of enough compute.
Models were moving towards Inference test time compute - the computational resources used when the model is actually deployed and making decisions. Reasoning capabilities enable the model to “think” through problems step-by-step (like the OpenAI o1 and DeepSeek R1 models) and , rather than simply producing an output based on its pre-trained knowledge.
New narrative:
Lower barriers to entry: This shift potentially allows smaller teams with fewer resources to develop competitive AI models.
Reshaping Investment Landscape: This change may impact capital allocation decisions in both public and private markets, particularly for companies heavily reliant on pre-training infrastructure.
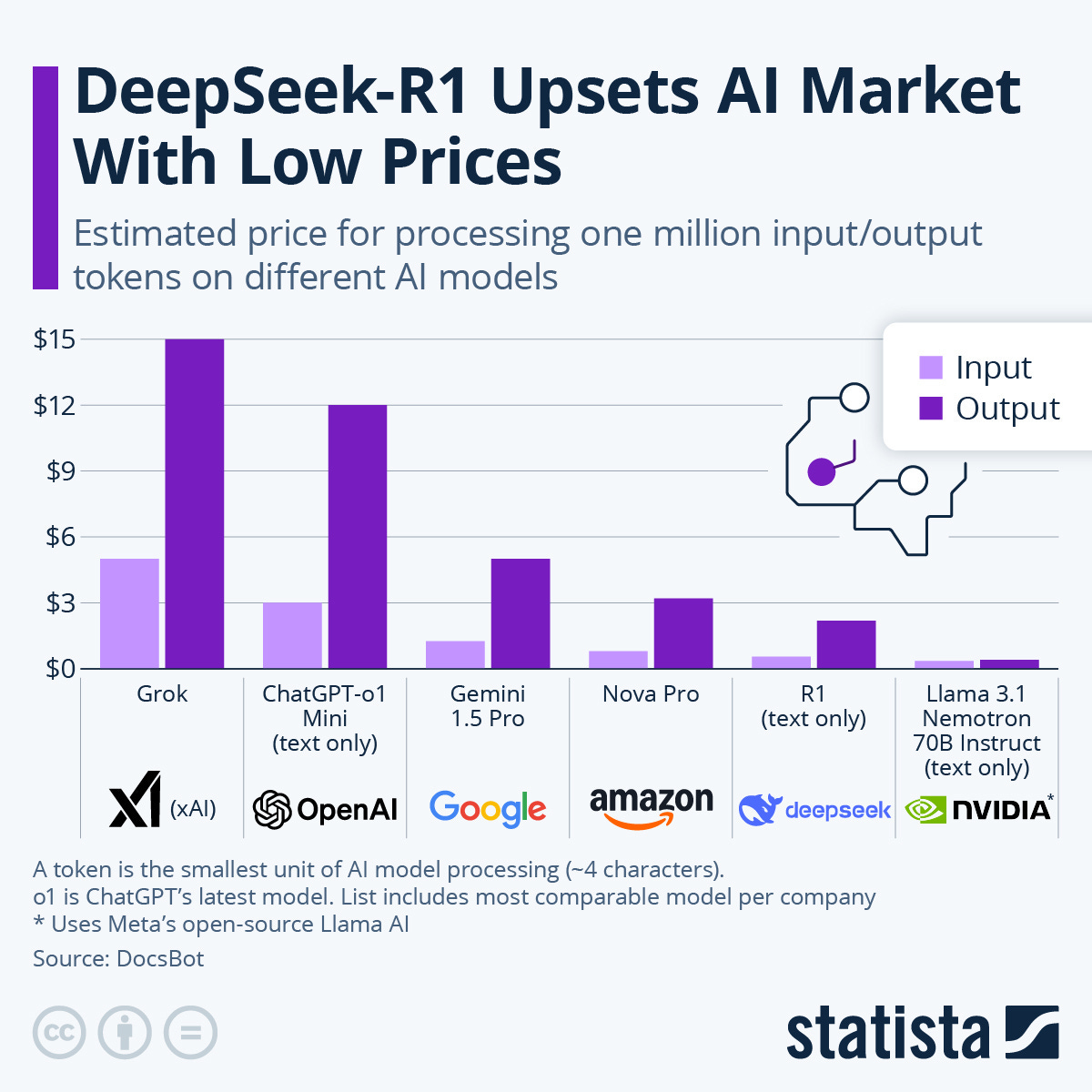
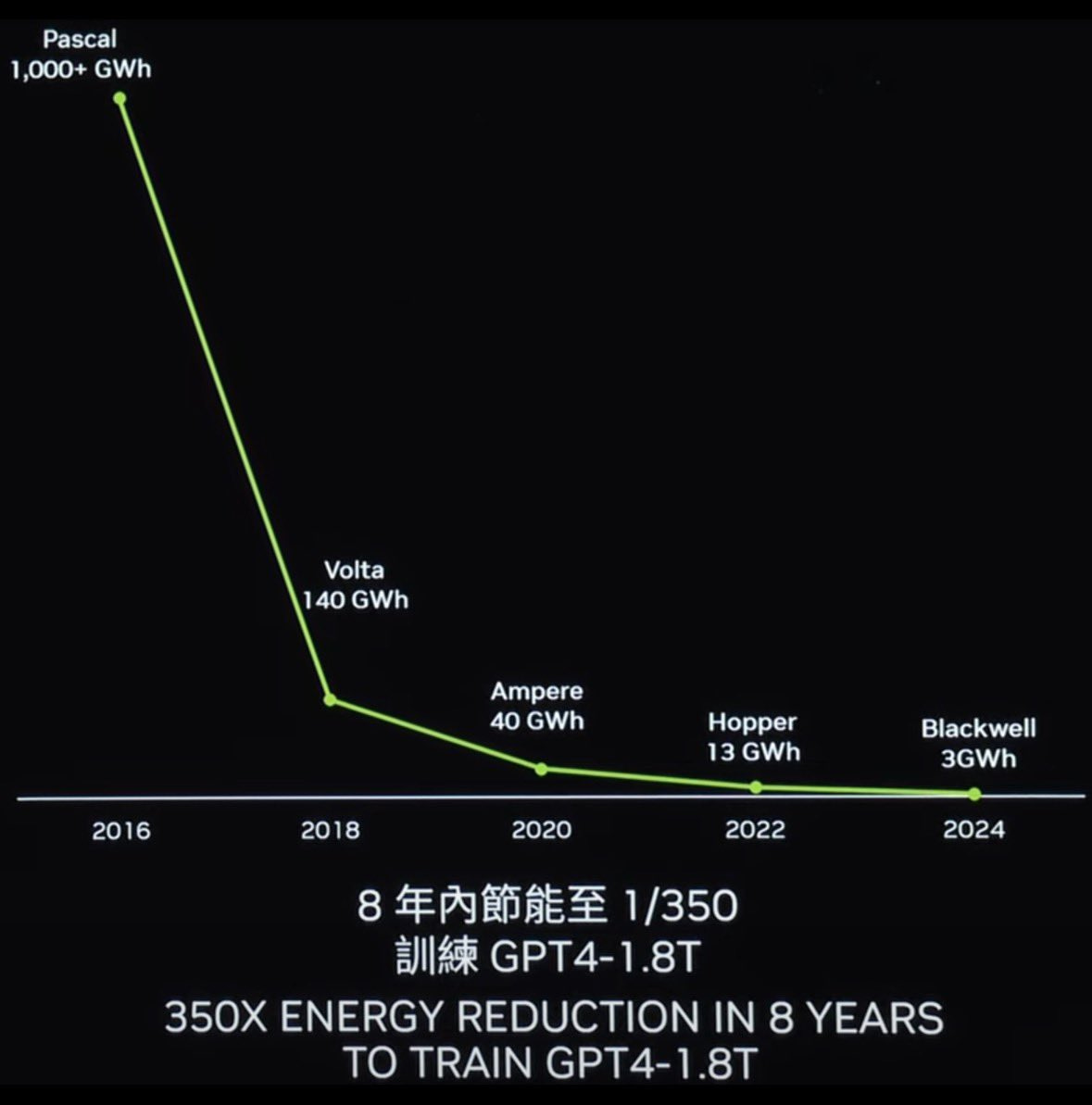
AI for everyone
As barriers to entry are lowered and models become cheaper and more efficient there will be more low cost models driving down overall costs and increasing adoption across consumers and enterprises.
How low do these curves go?
New narrative:
Adoption set to increase across use cases and verticals. Wrote more about it here
Big boost for applications with a lot of model API calls like AI Agents

The Capex debate
Constant bone of contention every quarter. As Big Tech capex spend continued to go up, fears of unused compute increasingly lingered. I wrote about it here, here and here.
Estimates went up again across the board even post DeepSeek. The message is clear, we still need to build out the infrastructure they said, but it is likely to become more ROIC (Return on Capital Invested) oriented and not just disappear. Inference needs as much (if not more) scaling as did pre-training.
New narrative:
Compute demand could actually increase as inference demand spikes up and models are deployed to solve more complex tasks. Some early signs of it have emerged already.
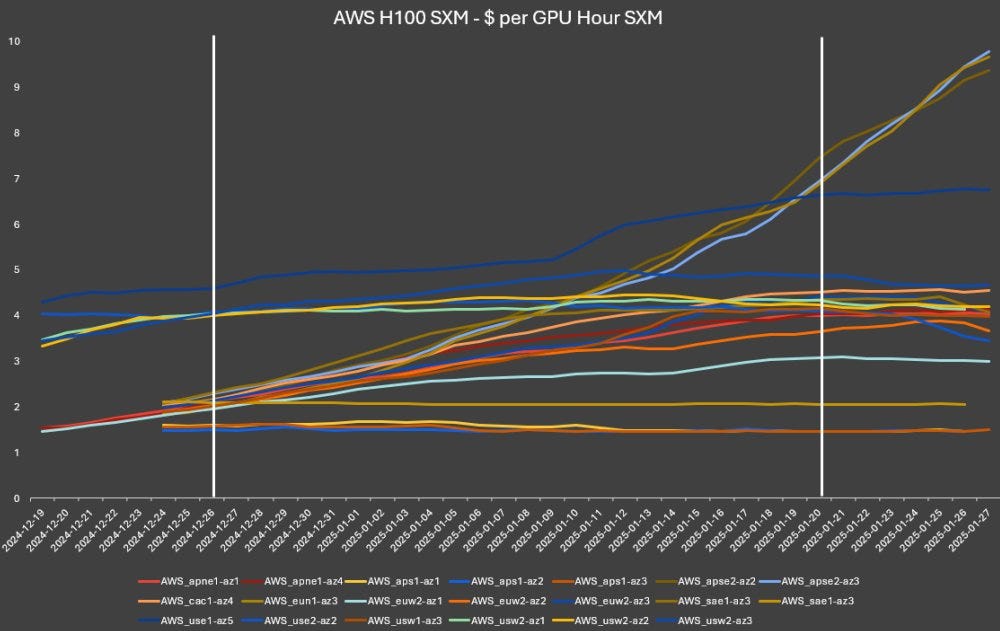
Then, more accessible models lead to widespread adoption, which drives up inference computing needs. It's reminiscent of how decreased computing costs in the internet era led to exponentially more computing overall.
The Nvidia debate
The tide seemed to suddenly turn against the biggest AI darling due to all of the above. Pre-training is where its moat was the most fortified, and as we move toward smaller, less compute heavy models there will be alternative players competing with it. All resulting in the weakening of its monopolistic position and therefore lower steady state market share, pricing power and margins.
But its not asleep at the wheel by any means. Its new inference line of chips and architecture is designed for better performance at scale.
Our upcoming release of NVIDIA NIM will boost Hopper inference performance by an additional 2.4x. NVIDIA Blackwell architecture with NVLink Switch enables up to 30x faster inference performance and a new level of inference scaling, throughput and response time that is excellent for running new reasoning inference applications like OpenAI's o1 model. - Nvidia Keynote
I see this as a 2x2 matrix between the TAM for AI GPUs and Nvidia’s expected market share.
Amidst the AI infra market frenzy, developments in the robotics and EVs space are flying completely under the radar where Nvidia also dominates.
Plus its CHEAPER than when it all began!
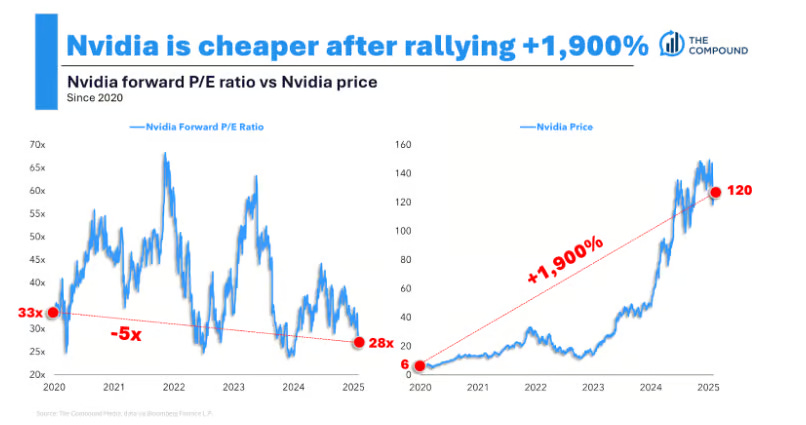
What probability weighted scenarios from above are we picking and how are we discounting them to the present?
The Application layer has arrived
Value creation vs value capture was another one of those ongoing debates. AI infrastructure providers seemed to be creating and capturing most of it (reflected aptly in their valuations and stock prices). I mentioned it here a while ago echoing the prevailing narrative.
Now when the consumer and enterprise facing apps see one of the largest line items in their cost structure shrink, does the application layer increasingly become the value creator and start capturing more value in the stack?

Two well known CEOs certainly had that in mind already, calling LLMs a commodity long before.
As AI becomes more capable and agentic, models themselves become more of a commodity, and all value gets created by how you steer, ground, and finetune these models. - Satya Nadella, Microsoft CEO

As increasingly powerful models like GPT-4 are being released, that view has actually not changed, in that LLMs are becoming more and more ubiquitous with the new models as they emerge. … The impact that we provide is upstream of those LLMs, and the transformational value of AI is really unlocked when organizations are able to deploy LLMs within their enterprise on their enterprise data in a secure way, allowing them to make operational decisions and actions using AI. - Alex Karp, Palantir
The DeepSeek R1 moment might be remembered as the catalyst that helped the market develop a more realistic understanding of AI's future landscape - one where innovation and efficiency matter as much as raw computing power and capital. Amidst these shifting narratives there were also some timeless lessons:
Technology is Deflationary: Cost curves in technology typically move in one direction - down. The question isn't if, but when and how quickly.
Never get married to your beliefs. Especially the ones where innovation and human ingenuity are trying to solve a problem.
And finally, the power of narratives:
Even as the brain is dying, it refuses to stop generating a narrative, the scaffolding upon which it weaves cause and effect, memory and experience, feeling and cognition. Narrative is so important to survival that it is literally the last thing you give up before becoming a sack of meat. - From the book You Are Now Less Dumb, David McRaney
Until next time,
The Atomic Investor